- 本日の作業内容
- 前回の宿題について
先週のWebテキストと動画で説明していたので,チーム数の違いについて大分分かってもらえたようです.しかし,今回も依然として9人が0点という残念な結果になってしまいました.どうしてチーム数が違っていることを平均値の算出に取りこめないのでしょうかね.
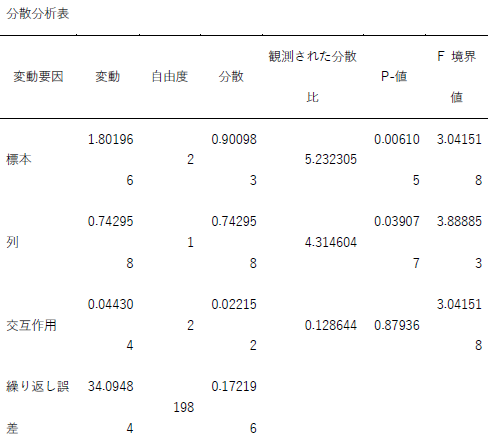
さて,まずは分散分析表ですが,きちんと作成すると以下のようになるはずです.
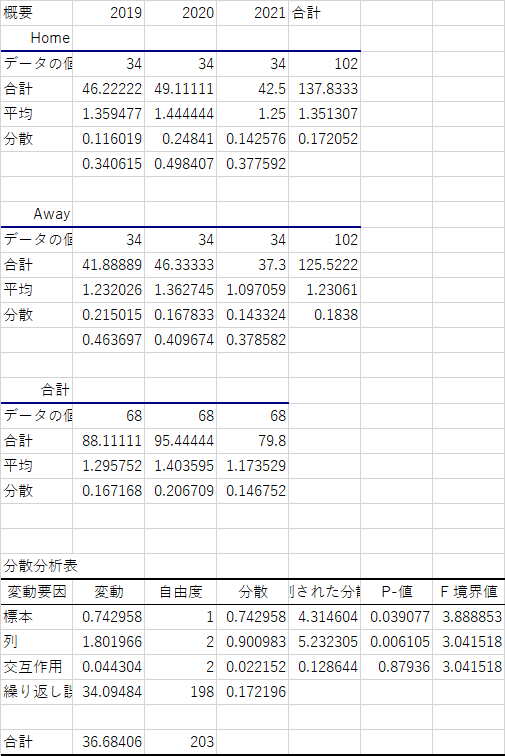
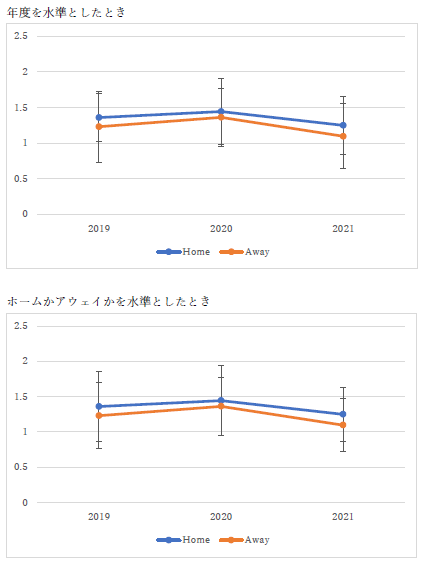
この結果を基にグラフを作成すると以下のように2種類の整理方法で表現できます.
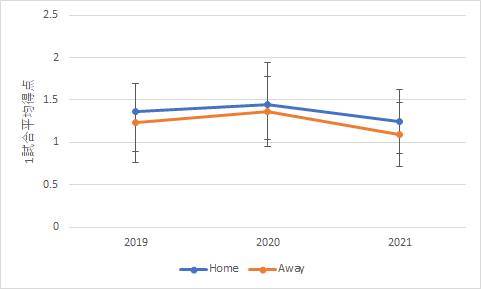
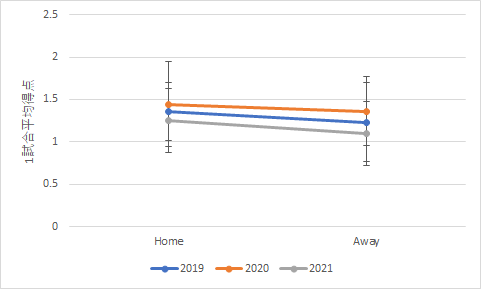
横軸を年度とした場合 横軸をホーム/アウェイとした場合 分散分析の結果は同じでも要因としての行と列をどう考えるかで,上のような2つのグラフが描けますが,同じ結果です.ただ,行と列を入れ替えて2回分散分析を行っている人が何人かいました.結果を見て気付いてくれていればよいのですが,表の中の数値は全く同じ物になっていましたね.なので,分散分析を2回行う必要はありませんでした.
結果としては以下のようにまとめられます.(有意なものだけ説明しています.)
- ホームチームとアウェイチームの1試合あたりの得点に有意な差が見られた.(主効果)
F 1981 = 4.31, p = .039
- 開催年度の間に有意な差が見られた.(主効果)
F 1982 = 5.23, p = .0061
年度毎にホームとアウェイのチームの得点を t 検定で分析すると,有意な差はありませんでした.しかし,3年間をまとめてみることができる分散分析では有意な差が見られました.ここが分散分析の意味あるところです.単年度ではばらつきの方が大きいと評価されますが,それが何年か続くと,基本的には毎年のことなので有意な差になるということです.また,年度間にも有意な差が見られました.ホームとアウェイの両方の得点が同じ傾向で変化しているので,これも2元配置分散分析ならではの有意差の検出となりました.
さて,例によって問題のあるものを見ていきましょう.
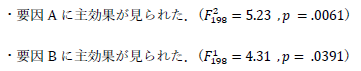
要因AとかBでは見ている人はなんのことかわかりません.きちんと説明しましょう.
表の中での数値の改行は不適切と前回も説明していたのですが…
貼り付ける図を間違えたようですね.最後までしっかり確認しましょう.
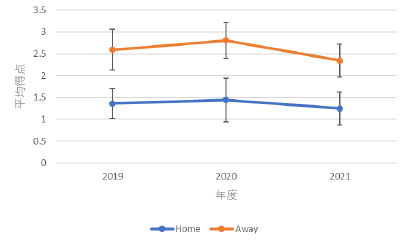
どうしてHomeの得点がこんなに低くなってしまっているのでしょうか?分散分析の方は合っていたので,なぜグラフが変なのかわかりませんでした.
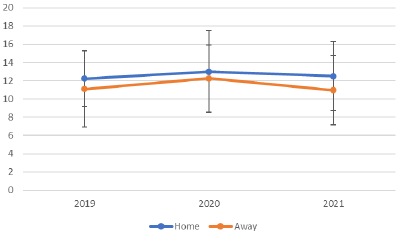
で,上のようなものが今回またしても 0 点となったものですね.これはグラフの縦軸の説明もない悪いものですが,どうして平均ということやってくれないのでしょう.

分散比の F や危険率の p はイタリックとしてください.また,上付きと下付きもきちんとしてください.
二元配置分散分析について学習しました.残差の求め方がややこしいので注意して下さい.また,分散分析表や結論の表現の部分もややこしいので,前回のWebテキストをしっかり見なおして下さい.
資料を参考に予習してください.
χ 2 検定について学習します.
- 適合度検定
Calc では標準で用意されている chitest() などの関数は「独立性検定」となっていますが,適合度検定はこの関数を使用して簡単にできます.
- サイコロの目の頻度
教室のCにおける乱数の発生が均等かどうかの検定を行ってみましょう.まず,以下のプログラムで36回サイコロを振った時の出た目の頻度を見てみます.
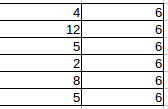
#include <stdio.h> #include <stdlib.h> #include <time.h> int main(void) { srand((unsigned) time(NULL)); int i, d, dice[6]; for(i=0; i<=5; i++) { dice[i] = 0; } for(i=1; i<=36; i++) { d = rand() % 6; dice[d]++; } for(i=1; i<=6; i++) { printf("%2d ", i); } printf("\n"); for(i=0; i<=5; i++) { printf("%2d ", dice[i]); } printf("\n"); return 0; }試しに行ってみたところ,私の手元では以下のようになりました.
1 2 3 4 5 6 4 12 5 2 8 5 Calc の方に,データを写しますが,確率的には各目は6回ずつ出るはずですので,下の図のようにデータを用意します.
- chitest() 関数
使用するのは chitest() 関数です.引数仕様は,実測値,期待値の順ですので,それぞれ実測と期待値のセルを選択します.今回の場合だと,結果を危険率 p で返してくれます.この場合は, p = 0.066 となるはずです.
- 検定結果
随分と目に偏りがあるような気もしますが,今回の結果はサイコロの目はそれぞれ1/6の確率で出るという帰無仮説を否定する危険率が .05 を超えていますので,棄却できないことになります.つまり,出た目の割合は有意に偏っているとは言えない,という結論です.
- サイコロの目の頻度
- 独立性検定
独立性検定とは,個々のデータが独立であるか,依存関係にあるかを検定で確認します.独立とはお互いに影響しあわないことで,座標軸の xyz はそれぞれ独立であるとか,よく聞くはずです.数学的には,「直交している」とも言います.
「独立である」とは,データの間に関連は無い,ということです.独立性検定の場合には帰無仮説としては,「独立である(関連はない)」となり,対立仮説が「独立でない(関連性がある)」となるので,ちょっとややこしくなります.
- プラシーボ効果
プラシーボ(偽薬)効果というものがあります.薬理作用が無いにもかかわらず治療薬だとして与えられると患者の症状が良くなる場合があることです.そのため,新薬の開発ではその薬が本当に効果があったのかについて薬理作用の無い物質を投与した場合との効能の違いを見ることが行われます.リンク先の資料の表1および表2のように,新薬と偽薬を投与して改善した人数と変わらなかった人数が出たとすると,この新薬には効果があると言えるかを,それぞれのデータについて独立性検定の観点で議論して下さい.
- 表1のデータについて
表1では実際に新薬を飲んで改善した人,しなかった人の行と,偽薬を飲んだのに回復した人としなかった人の行,それから,改善と変化なしの合計が入力されています.独立性検定の作業は,各欄の実測値から期待値を引いたものの2乗を期待値で割ったものの合計である χ2 を求めることです.
- 期待値
期待値は,あるセルを考えた時,その行の合計とその列の合計を掛けあわせ,全体の合計で割ったものになります.
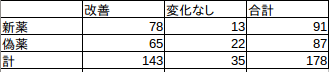
上の表であれば,例えば,新薬の改善(左上)であれば, 143×91÷178 で求められます.表計算ソフトなので,次のようにすればドラッグで他のセルの計算もできます.
= B$4*$D2/$D$4
もちろんセルの記号と数字はそれぞれの環境で異なりますので,自分のセルに合わせて下さい.では,各セルについて期待値を求めましょう.
- chitest() 関数
これでchitest() 関数を使用する準備ができました.どこかのセルで使用して下さい.実測値と期待値はそれぞれ自分が用意したセルを選択します.そうすると,危険率 p が計算されます.今の場合は, 0.065 ということで,それぞれのデータは独立である,という結論になります.実際の意味としては,今回の新薬の効果は有意ではなかったということです.
- 表2のデータについて
ちょっと数値が変わった表2についても検定を行ってみましょう.
- 期待値
- 血液型
PDF資料にある「ある集団の血液型分布」の例を見てみましょう.表は以下のようになっています.
血液型 A O B AB 計 男性 55 22 16 7 100 女性 40 32 24 4 100 計 95 54 40 11 200 χ 2 検定を行って資料の通りかどうかを確認してみましょう.
- プラシーボ効果
- 宿題
いつものレポート提出システムを利用して行います.
宿題の公開は原則として水曜日の18:00からとなります.また,提出の締め切りは翌週の火曜日の13:00までです.よろしくお願いします.
- ホームチームとアウェイチームの1試合あたりの得点に有意な差が見られた.(主効果)
Back