- 本日の作業内容
- 二元配置分散分析練習
今回はEXCELでの制約のために,全ての群でデータの個数が同じ場合を扱います.より一般的な,繰り返しの数が異なる場合についても当然できるのですが,この授業ではとりあえず繰り返しの回数が同じものだけに限定して実習します.
- データの準備
リンク先の資料を用いて練習を行います.まずは,準備してください.下図のようなデータがあらかじめ入っています.
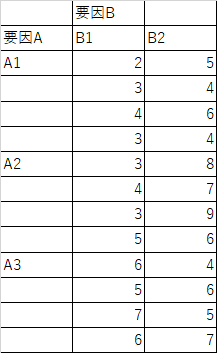
- ANOVA作業
EXCELのワークシートの一番左上からデータが始まっているとします.A2からC14までのセルを選択して,「データ」メニューから「データ分析」をクリックして「分散分析:繰り返しのある2元配置」を選択して,分散分析を実行しましょう.今回自分で入力する必要があるのは,「1標本あたりの行数」と「出力オプション」だけです.行数は各条件で4行ずつとなっているので4を入力し,分散分析表の出力先は適当なセルを選択しておきましょう.
出力される結果は以下のような表になるはずです.
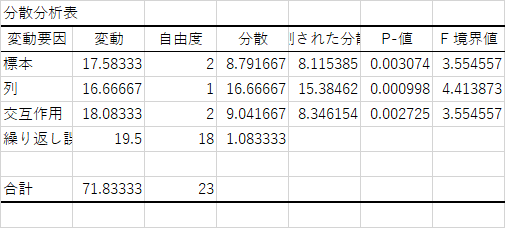
EXCELが出力する分散分析表で,「標本」というのは今回で言えば要因のA1からA3の条件によるものが対応し,「列」がそのままの意味の列,すなわち,B1とB2の条件による違いのことです.
- 結論
今回の二元配置分散分析の結論は以下のようにまとめられます.
- 要因Aに主効果が見られた.(F182 = 8.11, p = .0031 )
- 要因Bに主効果が見られた.(F181 = 15.38, p = .0010 )
- 要因AとBに交互作用がある.(F182 = 8.35, p = .0027 )
グラフも一緒に見ながら考えてください.
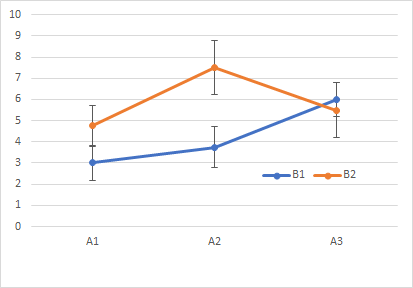
- 要因Aに主効果が見られた.(F182 = 8.11, p = .0031 )
- データの準備
- 演習
リンク先の資料のデータについて,二元配置分散分析により平均値について議論してください.
- 次回の予習範囲
今回のデータの取扱いについても,残念ながら不適切なものが多く,31人が0点ということになってしまいました.データをどう扱うかというのは,非常に重要な最初のポイントなので,今回も本当に残念です.では,どういうことか,まず説明しましょう.
2019年度と2020年度はJ1リーグは18チームで構成されていましたが,2021年はは前年度日程などの関係でチーム間で公平性が保たれない可能性が予見されるため,2部降格なしだったことから20チームで争われました.ということは,各節のゴール数は異るチーム数の足し合せなので,当然1チームあたりに換算しないとダメです.まずそこができていないと,比較できないデータを比較するということになり,意味がないので0点となります.
2019年度と2020年度のデータに関しては,ホームチーム9とアウェイチーム9で行われましたので,各節の得点を9で割って,1チームあたりの得点とします.2021年度についてはそれぞれ10チームずつですから,当然10で割って平均得点を出してから作業に入らないとダメです.
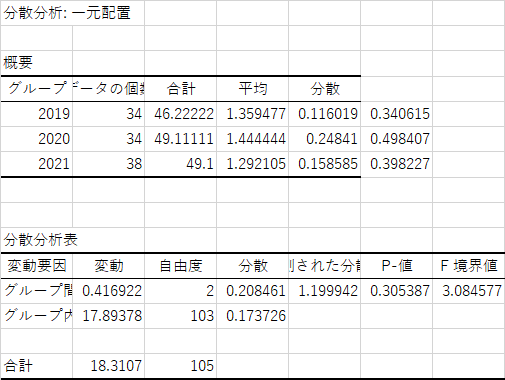
では,結果はどうなったでしょうか.まず分散分析表からです.
| ホームチームの分散分析表 | アウェイチームの分散分析表 | |
 |
 |
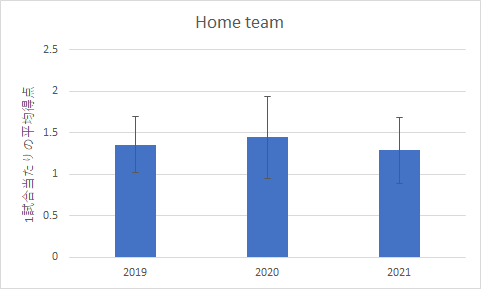
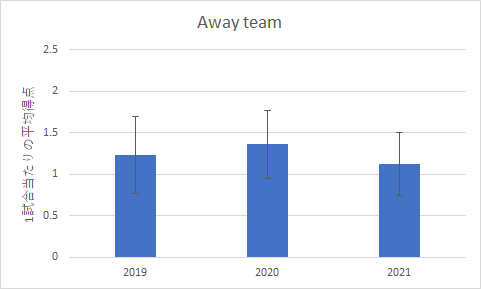
上の表を見ると,ホームチームについては危険率も大きく,年度の間に差は無いことは確実ですが,アウェイチームに関しては,危険率はぎりぎり5%を超えており,有意差はありませんが,有意傾向には確実にあると言えます.
分散分析表の概要の分散の右側にある数値は,前回同様標準偏差です.これを準備しておくと,グラフの作成が楽になります.ということで,エラーバー付きのグラフを作成すると下の図のようになりました.
 |
 |
|
| ホームチームの得点 | アウェイチームの得点 |
分散分析で有意差が出ないのでは,折角多重比較を学習したのに,意味ないじゃん!ということで,皆さんは楽ができて良かったと思ったのか,それとも,ちゃんとやりたかったと思ったのか,どっちだったでしょうかね.
ところで,分散分析とテューキー法は実は別個の検定作業なので,連動していません.テューキー法だけで最初から十分という考え方もあったりします.アウェイチームの方は分散分析で有意差が出るところとの差がわずかだったので,試しにテューキー法も試してみましょう.
今回の作業で使用する変数ですが,α は.05で,群の数 k は3,自由度 df は103となりますので,
q0.05,3,60 = 3.40
VW = 0.17486
を使って HSD を求めます.データの数が違っているので,2種類の値が出ますが,2020年度と2021年度の平均ゴール数の間には有意差が確認されました.そこまで行った人は以下のようなグラフも作成していました.
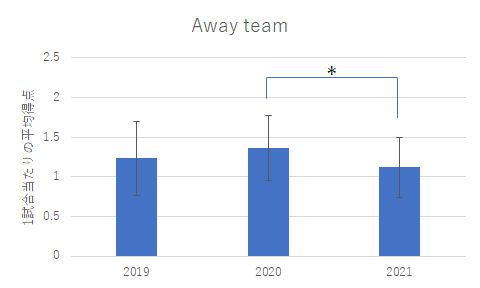
テューキー法による多重比較の結果の図
レポートの採点では上の図が無くても特に減点などはしていません.ちなみに,各年度でホームチームとアウェイチームでゴール数に差があるのかを t 検定で確認すると,危険率 p は以下の表のようになります.
| 年度 | 2019 | 2020 | 2021 |
| p | .20 | .46 | .056 |
2021年度のみ,ホームチームの方が得点が多いのが有意傾向にあるようです.考察としては,特に定まった見解なども無いので自由に考えてもらえば良かったのですが,私個人としては,Jリーグはヨーロッパや南米ほどサッカー文化や伝統が確立していないので,基本的にはホームチームのアドバンテージがほとんどないこと,2020年度は日程の大混乱で過密日程にもなり,硬い守備を確立することが難しかったのかなと思っています.2021年度は観客も入りましたが,声出し応援は禁止でした.また,2020年度に一部で試行されたスタジアムが勝手に応援音声を流すようなことも2021年度は無くなり,ピッチ上は選手の声がよく通る状況だったので,選手同士の連携が取りやすくなったことで失点が減ったのではないかと想像しています.私もスタジアムで応援している時に,選手が何を話しているのかがよく聞こえて,楽しくまた興味深く観戦できました.
さて,以下に例によって問題のあるものを挙げておきます.参考にしてください.

まずは上のような平均値ですね.チーム数を考慮しないで以降の作業を行おうとしているので,意味がない作業を続けたことになります.0点です.
ホームとアウェイのチームのゴール数を足していますよね.これも何を見たいのか,分からない整理の仕方ですので,0点です.
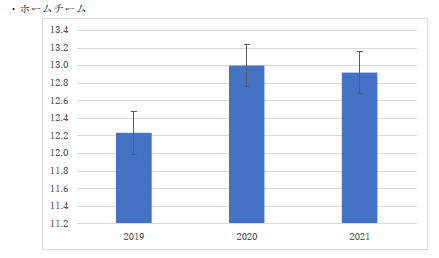
グラフの縦軸に原点がありませんし,エラーバーも間違っています.誤差範囲を加える時には,必ず「その他のオプション」から進んで,一番下のメニューの「ユーザー設定」で,自分で計算した標準偏差を使ってください.

上のようにゴール数が間違っている人も何人かいました.18チームや20チームでリーグは構成されていましたが,ホームチームとアウェイチームに分かれますので,ホーム9チーム,アウェイ9チームです.1試合平均のゴール数が半分になってしまっていますね.こんな得点の少いリーグでは誰も観戦に来ません.
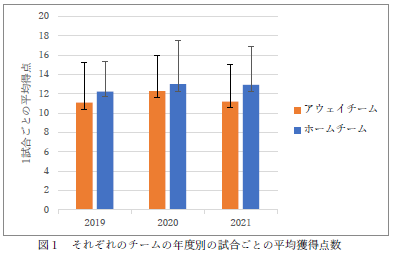
エラーバーがおかしいですね.上側と下側に同じ値が来ないとだめですよ.
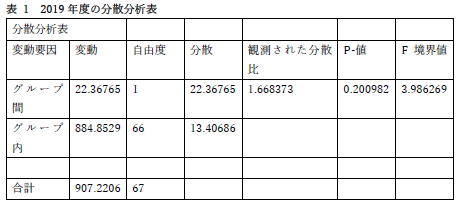
上のような分析を行っていた人も何人かいました.2つの平均値を比較するのであれば,分散分析は必要ありません.t 検定で十分です.
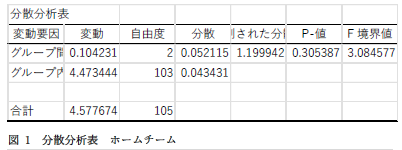
分散分析表は「図」ですか?
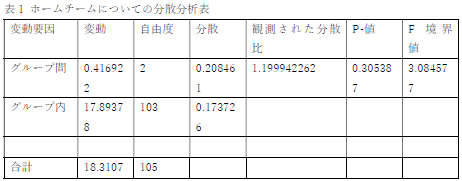
前回も指摘しましたが,表の中で数値が改行されています.数値を途中で改行するのは無しです.気をつけて下さい.
多重比較を行いました.分散分析と併用することで,どの平均値の間に有意な差があるかを見つけることができるものでした.データの解析の中で必要とする機会も多いので,きちんと理解しておきましょう.
資料を参考に予習してください.
次回は χ 2 検定について学習します.予習用の資料を参考に予習してください.
また,最後の授業なので,確認テストを実施します.準備の方もよろしくお願いします.
いつものレポート提出システムを利用して行います.
宿題の公開は原則として水曜日の18:00からとなります.また,提出の締め切りは翌週火曜日の13:00までです.よろしくお願いします.
Back