- 本日の作業内容
- Tukey (テューキー)法
多重比較を行う手法はいくつも提案されています.その中で,この授業では検出力が高く,かつ,バランスが取れているとして定評のあるテューキー法について実際に作業してみます.なお,厳密には各群のデータの個数が同じ場合をテューキー法と言い,群のデータの個数が異なる場合にはテューキー-クラマー法と言いますが,まとめてテューキー法と呼ばれることも多いです.
テューキー法で必要になるのは分散分析でも使用した群内平方和から求める分散 VW (分散分析の回のPDF資料では表3の vw2 とある群内変動の不偏分散)とステューデント化された範囲の表より得る q です.それらについて順に説明します.
- 群内の不偏分散
エクセルで分散分析を行うと得られる分散分析表の「分散」とある内の「グループ内」の方です.各群の中でのデータのばらつきを表します.
この値は独自に求めることも可能ですが,多重比較を行う前に分散分析を行っておけば簡単に求められますので,せっかくですからそのようにしましょう.
- ステューデント化された範囲の表
WindowsのExcel版はこちらです.これは次に説明する臨界差を出すために使用されます.通常の表計算ソフトではこれに関する関数は用意されていません.専用の統計解析ソフト(例えばRなど)を用いれば標準で入っています.
既存の表を使用しますので,危険率 p の値を計算することができません.あらかじめ想定する検定の水準(α が.05もしくは.01)に対応した部分を見て行います.また,表は群の数と自由度で q の値を探すことになっています.自由度は群内の自由度ですので,分散分析表の自由度のグループ内の方です.
- 臨界差 HSD
次に臨界差を VW と q から計算します.求め方は資料の式(4)もしくは(5)です.各群のデータの個数が等しい場合には式(4)を,異なる場合には式(5)を使用してください.
ここで,データの個数 ni と nj ですが,各群の平均値の差についてそれぞれ議論しますからグループAとグループBの平均値の間の差を議論する場合には ni と nj はそれぞれの群のデータの個数となります.
- 群内の不偏分散
- 例題
前回の宿題で使用した地域別の学級人数の表を使用して実習しましょう.生徒数について多重比較を行い,どこに有意な差が存在するかを確認します.
- 分散分析
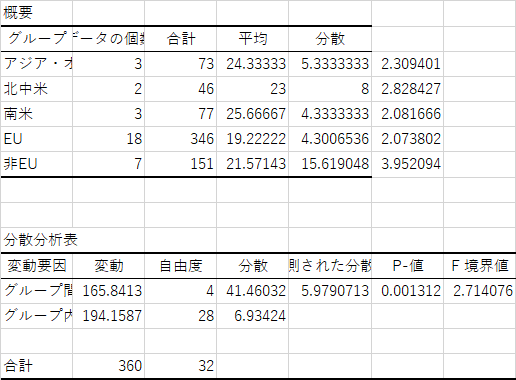
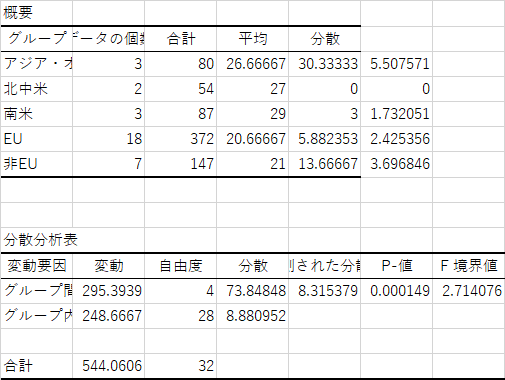
分散分析表は上に示す通りです.公立小で p = .00131,公立中で p = .00015 ですので,当然有意差がどこかにあります.
- 表の準備
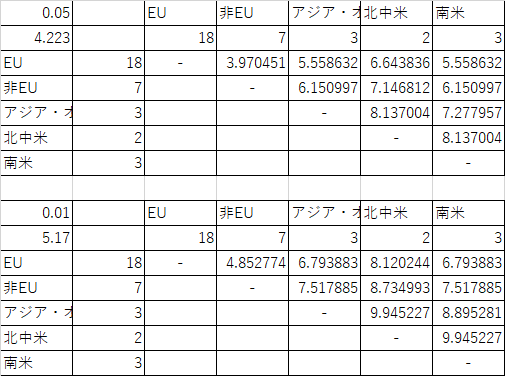
臨界差についての議論は各平均値間で総当りで行います.混乱してしまいそうなので,まずは,平均値とそれらの差についての表を作ります.表を作成するときには群を平均値の小さい順に並べ直して作成します.そうすれば,一番右上のセルが最も大きな差となり,そこから有意差の検討を始めれば良いからです.そこに差がなければおそらくどの平均値間にも有意差は出ないでしょう.
今回のデータを使用すると,以下のような表になるはずです.


公立小学校 公立中学校 それぞれの群の間の差を総当りで計算しますが,差は表の右上半分だけで構いません.正の値のところだけです.
- 臨界差の計算
今回は各データ群のデータの個数に違いがありますので,式(5)を使うことになります.ステューデント化された範囲の表から q を探しますが,分散分析における p が.00131 と 0.00015 だったので,α = .05と.01の2種類とも使用することになります.群の数は5,自由度は N - k = 33 - 5 = 27 ですので,それよりも少ないものとしては24を選ぶことになります.安全マージンを考慮して,ぴったりの数が無い場合には本来の値が入るべきところの1行上の自由度を選択しましょう.
今回のデータを用いて求めると, α = .05 で, q = 4.23 となり,α = .01 で, q = 5.17 です.
- 臨界差の表の作成
それぞれのデータの個数を考慮して表を作成すると次のようになるはずです.
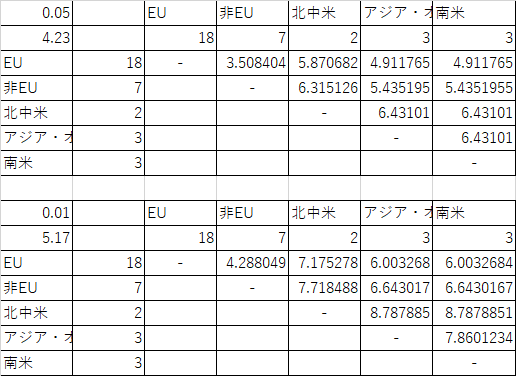
公立小学校 上:α=.05 下:α=.01 公立中学校 上:α=.05 下:α=.01 差の表と臨界差の表を見比べてどちらが大きいかを見ます.目で見比べるのは大変でしょうから,関数を使用しましょう.表のそれぞれの位置に対応する場所に次のような if() 関数を入れてみます.
=IF([差のセル]>[HSDのセル],1,0) もちろんセルの番地は自分の表に合わせてください.これにより,差の方が大きい場合には1が,そうでない場合には0が表示されます.
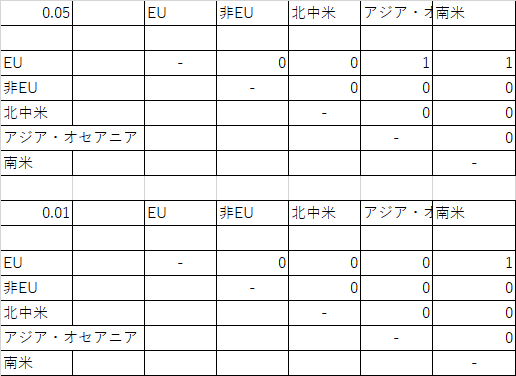
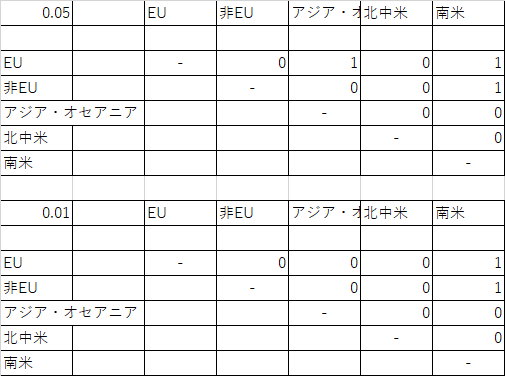
公立小学校 上:α=.05 下:α=.01 公立中学校 上:α=.05 下:α=.01 - 結論
テューキー-クラマー法による多重比較によって,EUと の小学校と中学校1クラスの平均人数の間にそれぞれ有意差があることが示された.( p < .05)
加えて,EUと南米,また非EUのヨーロッパ地域と南米の間で1クラスあたりの中学校の人数に有意な差があることが示された.( p < .01)
- グラフ
今回の多重比較の結果は下のようなグラフにまとめられます.
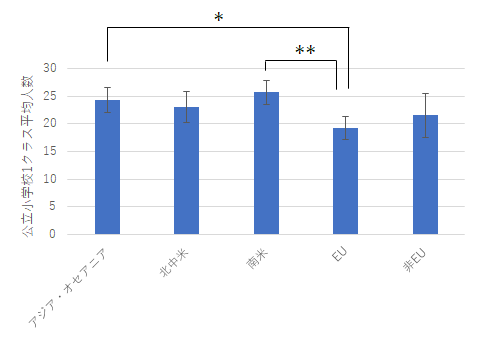
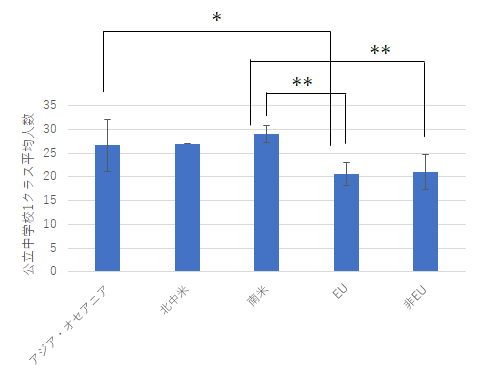
公立小学校 公立中学校 エラーバー付きのグラフにすることで,棒とエラーバーの重なり具合が見えるので感覚的にもよくわかります.
- 分散分析
- 次回の予習範囲
今回はとにかく驚きました.また,採点をしていて悲しくなりました.採点結果が0点という人が39人です.なんということでしょうか.
まずは,結果です.分散分析表は以下のようになったはずです.
「概要」の表の分散の右側は自分で加えて標準偏差です.エラーバーを描くための準備です.
| 分散分析表(小学校) | 分散分析表(中学校) | |
|
|
そして,グラフは以下のようになります.
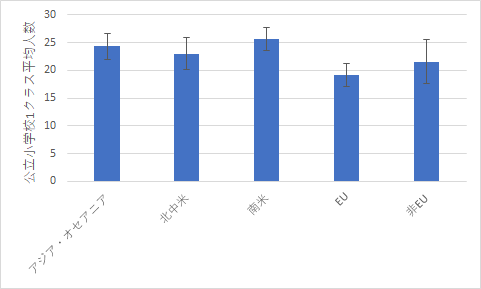
|
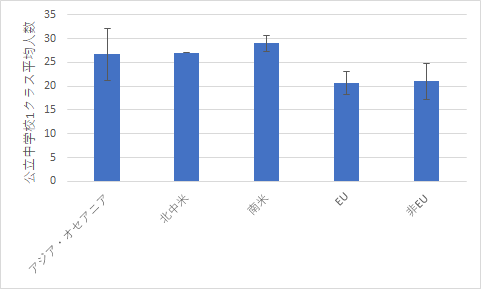
|
|
| 小学校の生徒数の比較 | 中学校の生徒数の比較 |
分散分析表の中にある危険率 (P-値) のところを見ると,小学校で 0.001312,中学校で 0.000149 となっていますので,これらの平均値の間には有意な差があることがわかります.
そして,考察ですが,一緒に載せていた世界教育水準ランキングを見てそこから何が読み取れるかでした.
実は,順位(順序尺度)ではなく,何らかの指標(比例尺度)を探したかったのですが,項目ごとに抜けが多くて厳密な比較ができない状況でしたので,順位を持ってきました.順位は比例尺度では無いので,それと学級の生徒数との相関を取るためには厳密にはいろいろと考慮しなければいけないのですが,えいやっと相関を見てみるとどうなったでしょうか?
小学校で r = 0.36, p = .037 (Φ = 31),中学校では r = 0.35, p = .044 (Φ = 31) となり,有意な相関があることがわかりました.すなわち,学級の人数が少いほど,その国の教育水準が高くなるとが示されました.今後の日本を背負う皆さんは教育問題などにも関心を持ってくださいね.
さて,ではいつものように問題のあったものを見ていきましょう.まずは0点となってしまったものですが,以下のようにデータを整理していました.
|
|
いろんな国の教育状況を見て考えようというのに,どうして公立小と公立中を比較するのでしょうか?

|
|
上のものはさらに謎です.クラスの平均の生徒数と順位は高さを比較できる量でしょうか?
今回もまたエラーバーがちゃんと作れない人がいました.動画で何回か説明しているのですが,未だにちゃんと出来ない人がいますね.
上のものは一見良さげに見えますが,前部のエラーバーの長さが同じなので,設定を間違えていますね.

こっちは,上と下のエラーバーの長さが違っています.こちらも設定を間違えています.
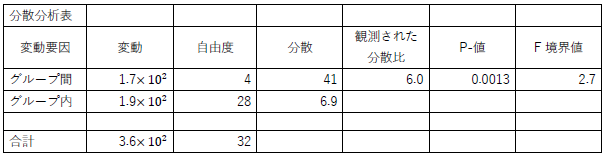
最後に下の表が気になったので,一応指摘しておきます.有効数字についてこれまで何度も指摘したので,このように整理したのだと思いますが,エクセルの分散分析表を貼り付けるだけのときは,ここまでしなくても大丈夫です.ただし,文中で値について何らかの記述をするときには,有効数字を意識してください.
分散分析について学習しましたが,結局分析とはどのような作業をすることなのか,統計的仮説検定について,もう一度よく見直しておいて下さい.
資料を参考に予習してください.
分散分析によって,データの平均値の間に有意な差が検出されたとしても,どのデータの間に有意な差があるのかはわかりません.そのため,各群の平均値の間の有意差を具体的に検討する手法として多重比較があります.今回はその中でもテューキー法と呼ばれる方法を実際に試してみます.ただし,これまでと異なり,表計算ソフトにはそれ用の関数は用意されていません.原理に即して手作業で行うことになります.
次回は2元配置分散分析について学習します.予習用の資料を参考に予習してください.
いつものレポート提出システムを利用して行います.
宿題の公開は原則として水曜日の18:00からとなります.また,提出の締め切りは翌週火曜日の13:00までです.よろしくお願いします.
今週の宿題についてですが,7月13日の夕方に一度公開したものの,7月14日の10:45に内容を変更しました.現在のものが正しい課題ですので,ご注意ください.
Back